
IMPORTANT ANNOUNCEMENT
Development and support of Willow is now discontinued. Willow
was removed from production
at UW on June 30, 1999. |
White Paper on Java Willow
Matt Freedman
Last modified September 26, 1997
Since 1990, the University of
Washington has spent a great deal of effort developing a uniform
set of interfaces to our library catalog and our extensive collection
of licensed bibliographic databases. The first result of this project
was Willow -- a Unix/X-Windows program. It was followed soon after by
WILCO (Character-Oriented Willow -- usable via any ASCII terminal), and
WinWillow (Willow for Microsoft Windows). This document presents an
architecture for the re-implementation of Willow in Java. It is meant
as a conceptual overview, not a detailed software design blueprint. It
assumes a basic understanding of the concepts
of the Java programming language. An understanding of the current
Unix/MS-Windows user interface and architecture, as described in the Willow Technical Report is also helpful, however
the nutshell version is as follows:
-
Willow provides a highly sophisticated yet easy to use interface for
searching bibliographic databases (i.e. library catalogs, journal
citation databases, encyclopedias, etc). It is characterized by
multi-field boolean searching, and convenient access to result titles
and summaries as well as full records. Especially useful are the
extremely responsive interactive browse-lists for choosing quickly from
the valid terms for most search-fields.
-
Willow has a three-tier architecture, where the middle layer consists
of "database drivers" that translate between the user
interface and the target database. Current drivers include one for the BRS/Search
engine that UW uses for our locally loaded databases, and one for the
standard Z39.50
internet database access protocol which allows us to use our client to
access a large number of bibliographic databases scattered around the
internet.
-
All three interfaces -- X/Windows, Microsoft Windows, and
character-only -- access the exact same database driver programs,
running on a Unix driver-server machine.
-
Willow's support for databases that contain anything other than
plain-text is rather awkward.
-
Willow is not deeply integrated with the web. You can configure a Web
page to launch Willow when a link representing a particular database is
clicked, but that is as far as it goes.
Java offers the promise of "Write once, run anywhere" (though
unfortunately that is still just a promise). Having only one program to
maintain instead of three, and getting a Macintosh Willow for free is
one big attraction of Java. A Java Willow applet also fits better into
the new world order of computing. Current Willow is inherently
application-centric. You start up Willow, and use its database chooser
interface to select from among the data sources that have been
pre-configured for you by the system administrators. The web, and the
vision of the future Javafied universe, is data-centric. The new Willow
is designed to fit this paradigm. With this model, instead of using
Willow to choose your data source, your web browser is your primary
interface to the information universe. You travel through the web via
whatever paths you choose to follow, until you hit a site that contains
a database of information you are interested in. There, you will find
the Java Willow applet embedded on a page. It will allow you to do the
sophisticated searching that the UW research community has come to
expect. But once you start looking at the retrieved documents, you have
the full power of the web at your disposal --pretty-printed HTML
displays, hypertext, and embedded multimedia objects -- because the
full-record results display is the web browser itself. Another
motivation for Java Willow is that we can change the acronym from
Washington Information Looker-upper Layered Over Windows (which
originally meant X/Windows, but now tends to connote a rather different
windowing system) to Washington Information Looker-upper Layered Over
the Web).
The incredible awkwardness of searching via HTML forms is probably the
biggest drawback to the current generation of web-accessible databases.
There are thousands upon thousands of web sites that have databases of
searchable content, fronted by extremely weak HTML forms-based search
interfaces. When Java Willow is complete, back-ends can be constructed
to allow it to talk to the most popular web-accessible search engines.
It could then be fairly easy to plug it into an arbitrary searchable
web site. The following are just a few examples of sites that would be
greatly improved by multi-field boolean browse-listed summary-viewable
searching. For each site listed, there are dozens or hundreds of
similar ones that would also be revitalized by Java Willow:
This is not to imply that any of the above sites are poorly implemented
-- in fact, they represent the current state of the art in what you can
with HTML-forms based search interfaces. The point is that this
paradigm is extremely limited.
And though searching with web-forms is vastly inferior to searching
with the standard Willow client, once you do get your hands on a result
record, these web-based systems are generally much more powerful than
Willow's result display. With original Willow you get plain ASCII text
only. On the web, well, you get web pages -- the sky is the limit. Thus
Java Willow is an attempt to get the best of both worlds.
The best way to understand the Java Willow interface is to just try it yourself!
For those whose browsers are not yet paying attention to the
"Write Once, Run Anywhere" slogan, screen shots are included
below. Also the major differences between Java Willow and standard
Willow are notated.
-
Search Window:
-
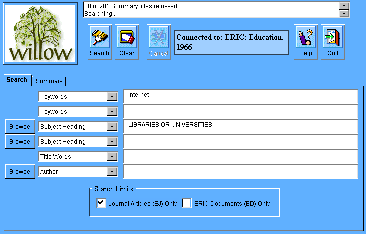 Click for full size image.
Click for full size image.
-
-
Differences with Standard Willow:
-
Search composition: The basic layout of standard Willow's search screen
translates just fine to the applet. Up to six type-in text fields,
with pop-up labels, optional checkable limit boxes, pop-up date-range
selector (not implemented yet), and buttons for Browse, Help, Clear,
and Search continue to serve us well.The Help subsystem
is now totally HTML based, and not built into the applet at all.
-
Database menu: Standard
Willow's built-in database chooser is not implemented in
this version. As mentioned above, the Web is your database chooser.
Nevertheless, the expandable outline paradigm is a good one, and is
quite hard to do properly in HTML, so we will probably add a built-in
chooser later.
-
Queries menu: The Name current query and Delete
a query functions are missing. Saving/loading query sets is
quite difficult in an applet. Java applets are currently not permitted
under any circumstances to touch the local file system or make a
network connection to any host other than the server they came from.
However, you could create an authenticated database of saved queries on
the web server. It would be a fairly large problem in and of itself,
and is definitely not a first-pass feature. Storing the queries
server-side is better in a way, because then you could get at your
saved queries no matter what computer you happened to be running the
applet on (i.e. even on public access terminals). This functionality
could be linked in with a system for automatically running certain
searches for people at regular intervals (i.e. an expansion of the UW's Zephyr
system).
-
Options menu: There are no user-settable options
yet. The Record Format options screen should be fairly
easy to implement a bit later on. Saving the options presents the same
difficulties as saving queries -- if we do it, they will have to be
stored in a passworded database on the server side.
-
Basic Mode: Willow's
basic mode -- a simplified version of the search screen,
with a single built-in browse list, designed for known-item library
catalog searching -- is not implemented yet. However it should not be
especially difficult to put together.
-
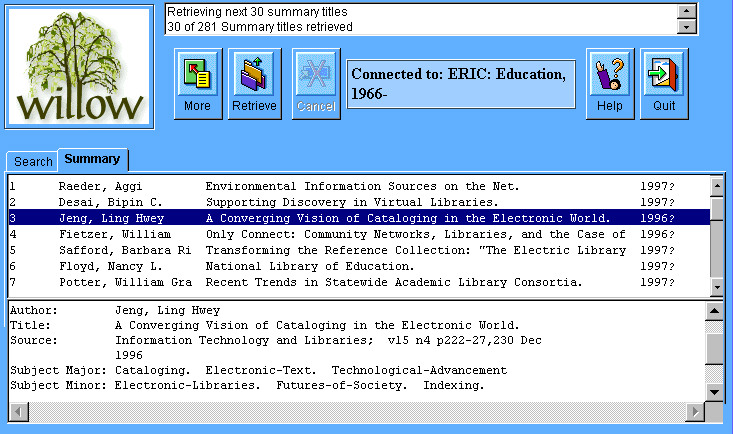
Summaries Window:
-
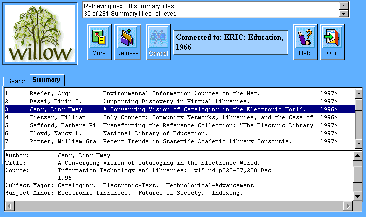 Click for full-sized image.
Click for full-sized image.
-
-
Differences with Standard Willow:
-
Layout: Again, the standard Summary window
appearance has not changed much as we move to Java. The list of titles
is unchanged, and a simple plain text summary body works well. It might
be nice to allow the possibility of HTML display within the summary
body, but including a Java HTML display component within the applet
running within the HTML-displaying browser seems a bit silly.
-
Save/Mail: Due to the applet security
limitations, we face the same problem as with saving search strategies
-- the applet can not write to disk, or make new network connections.
We could however have the web server send summary results via e-mail
back to the user. But for the time being, summaries are read-only.
-
Print: Having the applet do any printing itself
is currently impossible (but this should be coming in a future Java
release).
-
Record Retrieval Window:
-
 Click for full-sized image.
Click for full-sized image.
-
-
The full-record display is not part of the applet at all, instead the
applet asks its parent web browser to display the full record. Willow's
capabilities for saving, mailing, printing, and searching within a
record are already built in. In addition we get lots of new features,
such as all the display capabilities of HTML, hypertext links in the
records, and all kinds of multi-media object types embedded in records.
This web view is a big improvement over standard Willow's Full Record view.
-
-
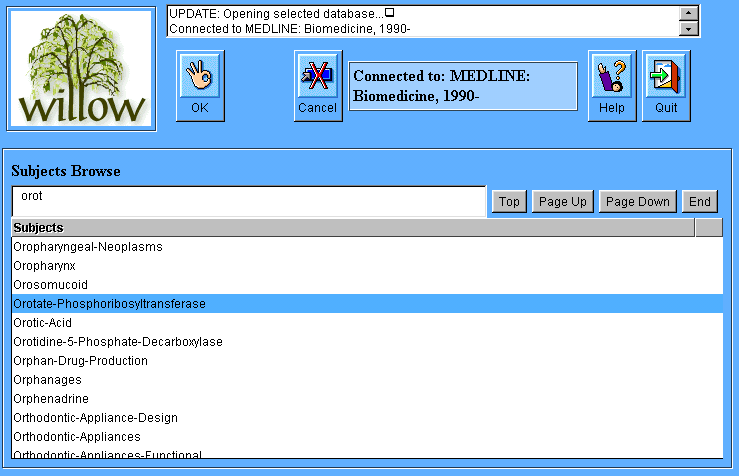
List Browser:
-
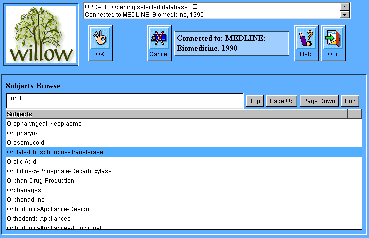 Click for full-sized image
Click for full-sized image
-
-
The update as-you-type List Browser is more or less the same as standard Willow's. The example
here, drawn from the MEDLINE database, shows that you just need to type
the first few letters of a complex medical subject-heading in order to
select it from the list of all possible values for the Subject field.
This is where Java Willow really stands out from HTML-based forms.
However it does require backend database support (which we had to
custom-build for BRS) so it may not easily translate to other backend
databases in the future.
The Java Willow prototype was architected with the primary goal of
getting a proof-of-concept version up as quickly as possible. It just
searches our current collection of databases (BRS and Z39.50), but is
designed with our plans for a second generation more universally
applicable Java Willow in mind. We used as much existing Willow
infrastructure as possible to do this. In this section I will first
outline the current architecture, and then our vision for what the
architecture will evolve into.
The Current Java Willow system can be thought of as five distinct
layers:
-
User Interface
-
The user interface is of course the Java Applet that the user sees and
interacts with. It is compatible with Java 1.0.x, and in theory should
run in the lowest common denominator of Java-capable browsers. We used
a number of add-on user interface components such as image buttons and
tabbed-windows to provide the functions that the standard Java user
interface toolkit (AWT) does not provide.
-
Java Backend
-
The backend is responsible for reading the configuration information
for the selected database, and for establishing a connection to the
database. There is a very clear line between the code that defines the
backend and the user interface (in fact, different people wrote each
module). The user interface and the backend are both downloaded
together to the browser as part of the applet, but as you will see, in
the next generation the backend is going to be running as a server-side
object, and the communication will be over the network.
-
The halves communicate by asynchronously passing message objects back
and forth. Messages are along the lines of "Connect me to this
database", "Here is the configuration for your
database", "You are connected", "Execute this
search", "Here are some result titles", "Here is a
URL for a full-record result". etc. The messages were kept as
abstract and high-level as possible. For now, the backend has to
translate the abstract Java message objects into standard willow/driver
protocol packets (this protocol is described in the Willow Technical
Report).
-
The backend gets the configuration information for the target by
reading the exact same Willow configuration files from our web server
that standard Willow reads. The files basically tell the user interface
what search-field labels etc. should be displayed to the user for each
database.
-
Connection Launderer
-
Ideally the backend would open a socket connection to one of our campus
Willow driver-server clusters, and send willow/driver protocol data to
it to establish a connection to the target database. However, because
of Java security restrictions the applet can only open network
connections back to the machine it was downloaded from. So the
connection launderer is a simple C program (run under inetd
on a Unix box) that pipes a connection from the Java Willow applet
backend to our database driver server.
-
It also intercepts full records retrieval results coming from the
driver, and instead of passing those along to the backend, it writes
them to a temporary file on the web server, and passes the backend a
URL it can use to get at the file. This is necessary because there is
no Java function for an applet to tell the browser it is running in to
open a stream of HTML -- instead the applet can only tell the browser
to open a specified URL.
-
Database Driver
-
The last two Java Willow layers are exactly the same as the bottom
layers of standard Willow. Database drivers are described in great
detail in Willow
Technical Report -- they are standalone unix programs that
translate between Willow and a given target database (BRS or Z39.50).
We run the drivers on a server cluster so that Unix Willow, MS-Windows
Willow, and Character-Oriented Willow can all share them. Java Willow
also connects to the same driver-server (via the connection launderer).
We made a few small changes to our existing drivers so that they can be
told to mark-up BRS and Z39.50 records in HTML, for prettier display in
the browser.
-
Database Engine
-
The database engine layer is of course totally unchanged for Java
Willow. The driver server makes a connection on behalf of any type of
Willow client to either a UW-loaded BRS database, or a remote Z39.50
compatible database somewhere out on the internet.
The architecture we are evolving towards is more of a standard
three-tier system.
-
User Interface
-
In the next generation the applet consists of the user interface alone.
It will be built to use full Java 1.1.x, and most likely the Java Foundation
Classes. We are hopeful that eventually a crop of browsers will
evolve that will uniformly handle Java 1.1.x and JFC, and we will no
longer be plagued by the browser-implementation dependent user
interface glitches we constantly see now. With JFC's more advanced set
of interface components, we hope to easily add the missing interface
features from standard Willow.
-
We also plan on looking closely at various "push"
technologies, to help solve the download time problem, as the applet
grows heavier and heavier with features. I.e. create a Java Willow
"channel" so that our classes only need to be downloaded
once.
-
Distributed Object Middleware
-
The current applet's backend module will be moved to the web-server
side, and thus not have to be downloaded to the browser at all. The two
halves will pass messages as objects over the network. The most likely
candidate technology for this is CORBA, though we have
not made a definite commitment yet. We already have a CORBA-enabled
prototype of Java Willow working. Due to the advantages of
object-oriented programming, by simply replacing the message-passing
module with a CORBA version, Java Willow's interface and backend pieces
became a CORBA client and server with virtually no code changes
whatsoever. The fact that CORBA is being used is totally invisible to
the interface and backend code -- only the message module knows about
it.
-
Since the backend is no longer part of an applet, it does not need to
launder its connections anymore, so the connection launderer layer goes
away. The backend will at first just connect directly to the existing
driver layers, but eventually the driver functionality will be replaced
by CORBA/Java objects as well.
-
Database Engine
-
The target databases will not need to change at all. We (and hopefully
others around the world who want to use the Java Willow client) will
write CORBA-servers that know about the basic set of Willow message
objects, and then translate those requests into whatever a new target
database needs to receive. If the database is CORBA compatible already,
it should be very easy. But if not, it still will not be too hard to
write new translators. For example we would like to write a
Willow/CORBA to AltaVista CGI translator -- allowing Java Willow to
serve as a search interface to that search engine.
Once this new architecture is in place (and Java implementations in
browsers have improved), Java Willow will be a viable alternative to
primitive forms-based search systems. Not to mention allow the
University of Washington to satisfy our user's demands for a totally
web-based information system, without taking away any of the
sophisticated features they currently enjoy with the "Willow
Classic" architecture.
For the longer term future, there are a number of other features we are
starting to think about.
-
Parallel Searching
-
We definitely want Willow to have the ability to connect to, and run a
query against several databases at the same time. The difficulty here
is not really technical -- with the architecture outlined above,
talking to several CORBA-based Willow backend servers at the same time
is not particularly difficult at all. The real problem is one of user
interface design -- how do you set up an interface for choosing
multiple databases? How do you display the available search-fields when
they may not be the same across the databases? How do you display the
results coming in from different servers?
-
-
Lateral Searching
-
One of the best things about current web-based searching is the ability
to do lateral searching. I.e. you do a subject search in some database,
then while looking at an interesting record, the author's name appears
as a hypertext link. You click on the name, and it launches a new
search for all items by that author. Our paradigm is for the browser to
display the results on a different page, not the applet itself. While
we can make certain field values like an author's name into a hypertext
link, it is not currently possible to send information back to the
applet on a different page by clicking it (if I am wrong, and there is
a way, somebody please let
me know!).
-
However, with the way the web is evolving with the Web Consortium's
standard Document Object Model,
I am hopeful that eventually it will be possible to achieve this higher
level of integration between applet and HTML page.
-
-
Database-Specific Extra Functions
-
One of the goals from the very outset of the Willow project has been to
keep Willow as generic as possible -- it is designed to work well with
any bibliographic database, and does not incorporate features that
cater to any one specific type of data. This philosophy continues to be
an integral part of the Java Willow design. However, it is very easy to
come up with long lists of specialized functions that would be very
nice to have for some target databases -- for online library catalogs
it would be great to be able to talk to the circulation system to renew
and reserve books etc., for medical databases an integrated way to
quickly look up terminology in an online Medical dictionary would be
terrific, etc. etc.
-
-
One approach to adding special features without violating our
neutrality policy is to take advantage of Java's object-oriented
architecture -- especially the Java Beans API
-- to design a structure where database-specific user interface
modules could be downloaded into Java Willow as needed, depending on
the currently selected database(s).
-
Another approach for this sort of thing is to bypass Java entirely.
Instead, use standard web techniques to provide the extra functionality
in the browser's display of the result records. For example, we already
have an experimental system in place where a "Retrieve
Full-Text" link appears in the HTML display of retrieved journal
citations from MEDLINE. When you click the link it runs a perl/CGI
script that checks with the online journal full-text publishers we have
licenses with, and if possible, it will actually download the entire
referenced article to your web browser.

 Click for full size image.
Click for full size image.
 Click for full-sized image.
Click for full-sized image.
 Click for full-sized image.
Click for full-sized image.
 Click for full-sized image
Click for full-sized image
